Alta disponibilidade e load balance HTTP com HAProxy
Alta disponibilidade em serviços web é indispensável para o sucesso de um negócio na Internet. Em uma loja virtual seus visitantes podem desistir de navegar se sua página demorar muito tempo para carregar, seus potenciais compradores podem desconfiar da baixa qualidade do serviço e irem procurar o que querem em outra loja. Sem contar o trabalho necessário para reestabelecer o serviço. Recuperando backups porque dados foram salvos parcialmente devido a um shutdown forçado do administrador de infraestrutura que estava desesperado.
Este artigo irá explicar como utilizar o HAProxy para criar um ambiente de alta disponibilidade com balanceamento de carga. Não é intenção explicar a construção do ambiente completo, da aplicação ao banco de dados, pois o assunto é extenso e pode variar muito de acordo com a tecnologia utilizada na sua aplicação. Então aqui vou explicar apenas um pouco da arquitetura, focando em uma aplicação para o frontend do ambiente de alta disponibilidade. Que no final das contas é uma parte muito importante do ambiente de HA (i{High Availability}i) que não pode ficar indisponível para o cliente em momento nenhum.
Cenário de alta disponibilidade
O cenário da REF{cenario} é um exemplo de arquitetura simples de alta disponibilidade, com um sistema web composto por três camadas de servidores: firewall, aplicação e banco de dados. Na camada de firewall há um servidor que recebe todas as conexões provenientes da Internet, neste caso normalmente é suficiente um servidor de backup, que é ativo automaticamente quando é detectada a falha no firewall mestre. Na camada de aplicação consideramos múltiplos servidores provendo a mesma aplicação, se um servidor tiver problemas os outros podem dar conta do serviço. O mesmo vale para o banco de dados.
![Exemplo de arquitetura de alta disponibilidade para aplicação web]./alta-disponibilidade-e-balanceamento-de-carga-http-com-haproxy/cenario.png)
Note que na prática o esquema todo não é tão simples assim. Garantir o funcionamento da aplicação em mais de um servidor ao mesmo tempo pode ser bem complicado se analisar os detalhes técnicos, como compartilhamento de cookies/sessões, rotinas agendadas e até a manutenção de arquivos. E garantir consistência e redundância em um banco de dados não é uma tarefa fácil, basta olhar alguns manuais pela Internet para entender que não é apenas um desenvolvedor que pode manter este ambiente. Até porque isso é trabalho para um administrador de infraestrutura e/ou DBA.
Como indiquei no início deste artigo, a ideia é focar no frontend do ambiente de alta disponibilidade. O frontend no cenário acima é o servidor de firewall, que está exposto ao à Internet e é por onde todas as conexões de usuários "entram no ambiente de HA". No futuro pretendo explicar o uso de outras aplicações para HA tanto no frontend quanto na aplicação web e banco de dados. Este artigo não explicará como criar o servidor de firewall backup, já estou montando outro artigo sobre este assunto para publicar aqui no site.
Um pouco mais sobre o HAProxy
O HAProxy é oferecido como um confiável balanceador de carga de alto desempenho para HTTP e TCP. Na prática ele recebe as conexões dos usuários e atua como um proxy, criando um canal entre o usuário e um dos servidores de aplicação. Há benchmarks bem interessantes indicando desempenho de mais de 40 mil conexões por segundo em um hardware já considerado ultrapassado com rede de 10Gbps.
Esta aplicação possui alguns mecanismos interessantes para escolher o servidor web que deve encaminhar a solicitação do usuário. Dentre as estratégias de escalonamento suportadas as mais importantes, no meu ponto de vista, são:
Round-robin: Onde o servidor é escolhido de forma circular, independente da carga em cada um dos servidores de aplicação;
Menos conexões: Onde o servidor com menos conexões é escolhido, o que garante que o servidor mais ocioso seja utilizado;
Cookie: Onde o HAProxy tentará sempre indicar o mesmo servidor que o usuário conectou pela primeira vez;
Hash de IP: Neste caso a aplicação irá escolher o servidor de acordo com o IP.
Dentre os mecanismos acima, apenas o mecanismo de cookie não é um escalonador do HAProxy, ou seja, deve ser combinado com o escalonador round-robin ou de menos conexões. O mecanismo de cookie ou o escalonador por hash de IP são muito importantes para garantir que seu cliente não perca a sessão da aplicação HTTP. Sem isso seu usuário pode ser "deslogado" da aplicação quando o escalonador trocar o servidor de aplicação. O uso do escalonador de menos conexões é muito útil em casos onde as conexões demoram a ser fechadas, nestes casos evita-se que por uma "sorte" um servidor seja sempre escolhido para as conexões mais demoradas.
Ambiente de testes
Para testar o ambiente montei um conjunto de máquinas virtuais. O host destas máquinas virtuais era um Quad Core com 8 Gb de RAM e executava além da máquina do HAProxy duas máquinas virtuais com as aplicações web e banco de dados e uma máquina virtual que realizava as conexões repetitivas de teste através do HAProxy. A situação pode ser visualizada na REF{testemaquinavirtual}.
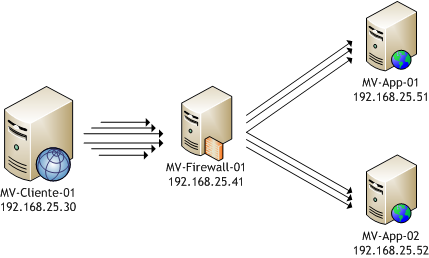
Neste artigo vou apresentar as configurações utilizando os IPs indicados no esquema da REF{testemaquinavirtual}. Todas estas máquinas estão ligadas em um mesmo switch gigabit em uma mesma rede. Como no meu caso utilizava uma rede virtual da própria plataforma de virtualização, a comunicação não era nem mesmo enviada ao switch. O ideal é manter apenas a máquina com o firewall conectada a Internet, e manter as demais máquinas em uma DMZ (zona desmilitarizada). As máquinas utilizadas são (todas com sistema operacional Debian 6):
MV-Cliente-01 (IP 192.168.25.30, 2 Cores + 1024 GB RAM): Nesta máquina foi instalada a aplicação Apache Bench (do pacote
apache-utilsno Debian). Esta aplicação permite criar múltiplas conexões a um mesmo endereço e também cria um relatório estatístico básico com as informações do teste;MV-Firewall-01 (IP 192.168.25.41, 2 Cores + 1024 GB RAM): Esta máquina é que executa o HAProxy;
MV-App-01 (IP 192.168.25.51, 2 Cores + 512 GB RAM): Esta máquina possui a aplicação web que será servida aos clientes;
MV-App-02 (IP 192.168.25.52, 2 Cores + 512 GB RAM): A segunda máquina que possui a aplicação web.
Configuração do HAProxy
Você pode compilar o HAProxy a partir do fonte, disponível no site do HAProxy. No Debian é bem mais fácil instalar através do apt-get.
# Primeiro de tudo, entre no modo ROOT, no caso do Debian e demais variações:
su
# Instalando o HAProxy
apt-get install haproxy
O próximo passo é editar o arquivo /etc/haproxy/haproxy.cfg. O arquivo original possui vários exemplos, crie um novo arquivo e insira o conteúdo abaixo se quiser configurar conforme o ambiente exposto na REF{testemaquinavirtual}.
# Nesta seção informamos parâmetros gerais do HAProxy
global
# Qual o número máximo de conexões?
maxconn 3000
# Qual é o usuário que o HAProxy deve usar no Debian?
user haproxy
# Qual é o grupo de usuário que o HAProxy deve usar no Debian?
group haproxy
# Indicamos que a aplicação deve executar como um daemon
daemon
# Quantos processos do HAProxy devem ser executados?
# Não faz sentido utilizar mais de um com apenas um núcleo de processador
nbproc 1
# Nesta seção informamos parâmetros para o frontend and backend
defaults
# Modo HTTP, já que vamos servir páginas por HTTP
mode http
# Habilitamos as estatísticas
stats enable
# Definimos um usuário e senha para acesso as estatísticas
stats auth usuario:senha
# Ocultamos a versão do HAProxy
stats hide-version
# Informamos que a página de estatísticas deve recarregar a cada segundo
stats refresh 1s
# Indicamos qual a URI vamos acessar para ler as estatísticas
stats uri /estatisticasdohaproxy
# Aqui escolhemos o escalonador
balance roundrobin
# A opção abaixo força o HTTP 1.0, liberando as conexões mesmo
# se o servidor servir em HTTP 1.1 com KeepAlive ativo no cliente
option httpclose
# Indicamos ao HAProxy encaminhar o IP do usuário ao servidor de aplicação
option forwardfor
# Informamos a chamada que deve ser feita no servidor de aplicação
# para detectar se este está online ou offline
option httpchk GET / HTTP/1.1\r\nHost:\ localhost
# Indicamos qual é o tempo máximo de conexão do backend
timeout connect 3000ms
# Indicamos qual é o tempo máximo de espera de resposta do backend
timeout server 50000ms
# Indicamos qual é o tempo máximo de espera de comunicação do usuário
# com o frontend (o firewall)
timeout client 50000ms
# Definimos a porta de entrada de conexões
frontend HA-HTTP
# Indicamos qual é a porta no firewall para entrada
# Neste caso é necessário escolher a porta 80, de qualquer interface (*)
bind *:80
# Indicamos qual é o número máximo de conexões no frontend
maxconn 3000
# Indicamos qual é o backend que deve servir esta porta
default_backend App-Servers
# Aqui definimos os servidores de backend (de aplicação)
backend App-Servers
# Associamos ambos os servidores
# indicando que deve ser utilizado um cookie para persistência
server App01 192.168.25.51:80 cookie HAP check
server App02 192.168.25.52:80 cookie HAP check
Agora basta salvar o arquivo e reiniciar o serviço (ainda como ROOT):
/etc/init.d/haproxy restart
Ambiente pronto para os testes!
Testes com o HAProxy
No ambiente que foi montado, basta acessar http://192.168.25.41/haproxyinfo para observar a situação do HAProxy (REF{haproxy}). É possível ver o número de conexões, os valores máximos atingidos até o momento, o volume de dados trafegados pelo HAProxy e também a situação de cada servidor de backend.
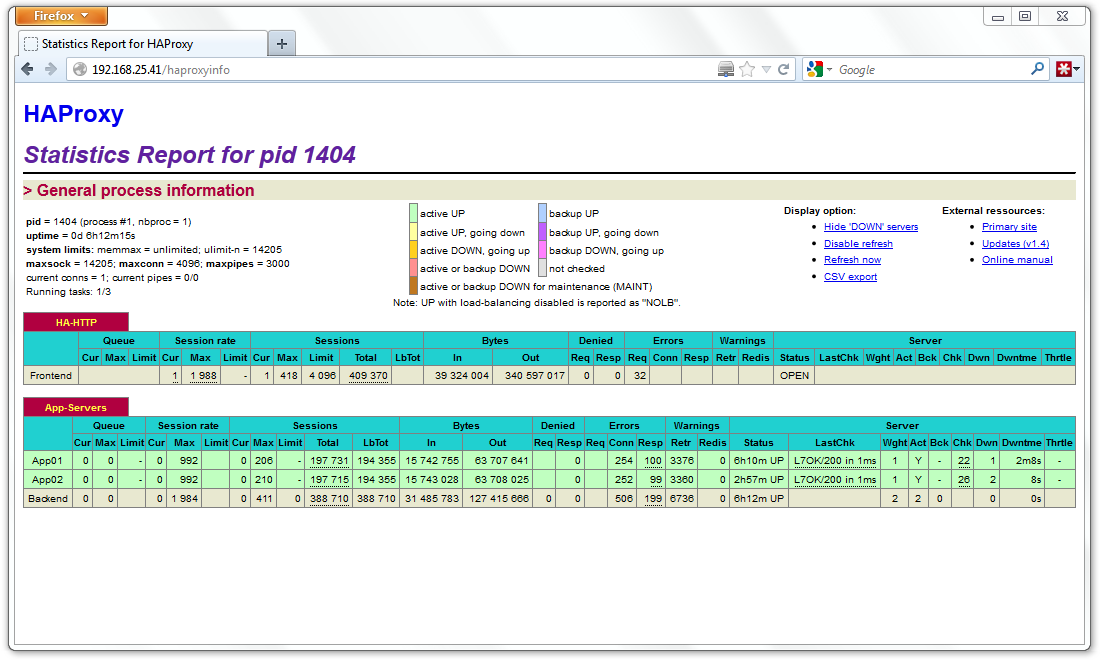
Os testes foram feitos apenas para avaliar o comportamento da aplicação. Tentei realizar alguns testes de desempenho porém ao utilizar máquinas virtuais os resultados foram muito similares pois as máquinas compartilhavam o mesmo hardware, desta forma não apresentaram-se resultados consistentes onde é possível observar os gargalos. Para gerar as cargas utilizei os seguintes comandos dentro da máquina virtual cliente:
# Sintaxe básica do Apache Bench
# ab -c <numero> -t <numero> URL
# -c <numero> (número de conexões concorrentes)
# -t <numero> (tempo em segundo para teste)
# URL (URL utilizada no teste)
ab -c 10 -t 30 http://192.168.25.41/
ab -c 50 -t 30 http://192.168.25.41/
ab -c 100 -t 30 http://192.168.25.41/
ab -c 300 -t 30 http://192.168.25.41/
ab -c 600 -t 30 http://192.168.25.41/
Na REF{haproxy-gd} há um print do monitoramento logo após parar a máquina virtual responsável pelo App02. No momento estava realizando o teste de 600 conexões concorrentes. Alguns segundos depois, o HAProxy marca o servidor de backend como offline e automaticamente passa a conectar apenas no App01. Neste caso o desempenho cai, porém o serviço não fica offline.
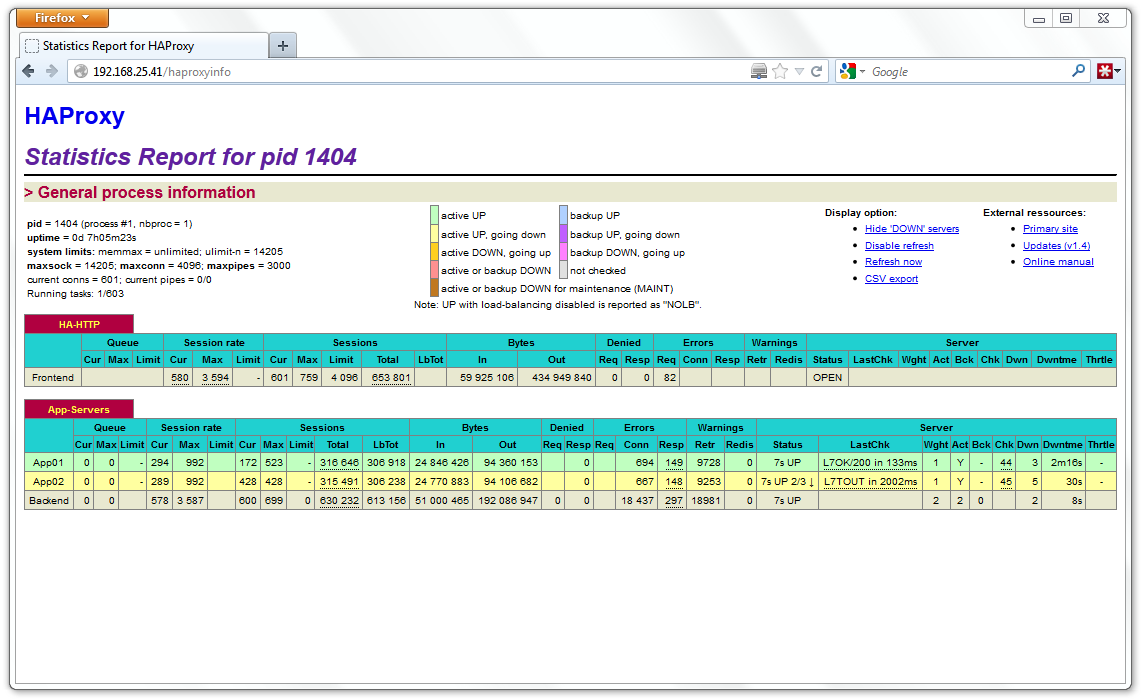
Com ambos servidores ativos, consegui até 3.000 conexões simultâneas por segundo nos resultados do Apache Bench. Não é possível confiar nas estatísticas do HAProxy. Se utilizar dois processos (nbproc 2) a página de monitoramento intercala entre ambos os processos e não apresenta resultados consolidados.
Se ambos os servidores ficarem offline as conexões são recebidas e o HAProxy mantém a conexão até que um servidor fique disponível. Se muitas conexões acumularem o timeout configurado no HAProxy é responsável por eliminar estas conexões. É claro que se houverem muitas conexões e o timeout for muito alto o firewall poderá ficar offline também. Há outras técnicas para resolver esse problema de DDoS.
Note que o Linux possui algumas restrições quanto a quantidade de conexões simultâneas, relacionadas ao número de descritores de arquivos. Se algumas variáveis não estiverem devidamente ajustadas no kernel você não conseguirá chegar um grande número de conexões simultâneas. Dê uma conferida nas variáveis somaxconn, portrange, tcp_fin_timeout, netdev_max_backlog, file-max, ulimit... e outras.
Conclusões
Na prática a ferramenta é muito interessante para implementar um ambiente de alta disponibilidade, o balanceamento de carga é consequência. Há como configurar os servidores no esquema de master/backup, tendo assim um sistema de alta disponibilidade sem o balanceamento de carga. Não faz muito sentido se o hardware está disponível sempre, mas se você pagar a infraestrutura pelo consumo de recursos (processador + memória) talvez lhe interesse.
Com relação ao processamento e consumo de memória, não consegui chegar ao limite de recursos no ambiente, o gargalo era o sistema de virtualização. Por algum motivo não conseguia trafegar mais de 100 megabits nas máquinas virtuais. O tamanho da página com certeza mudaria os resultados dos testes feitos. Uma página maior ocupará por mais tempo o firewall que obviamente demandará de mais recursos para atender mais conexões simultâneamente. O uso de um ou dois processos não mudou muito os resultados, acredito que o uso das máquinas virtuais também colaborou para isso.
A aplicação pareceu bem estável, não indisponibilizando as conexões dos clientes, apenas atrasando a resposta mesmo quando um dos servidores ficava offline. Esta aplicação não é exclusiva para HTTP, ela pode servir outras conexões TCP e balancear a carga de diversas aplicações que utilizem TCP.
Creio que os próximos testes envolverão a comparação entre outras aplicações com a mesma funcionalidade, como o Pound e o CrossRoads. Precisarei de máquinas físicas separadas para o resultado apresentar resultados consistentes. Há outros cenários de alta disponibilidade que envolvem o uso de aplicações de caching no frontend do ambiente. Estas aplicações não podem ser comparadas com este tipo de aplicação diretamente, mas podem isolar e diminuir a carga nos servidores de backend, em breve criarei um artigo explicando uma destas aplicações.