Replicação de dados com GlusterFS
Para projetos de alta disponibilidade é fundamental o uso de serviços redundantes: um banco de dados replicado, um link de dados de dois fornecedores, múltiplos hosts de VM com live migration, energia elétrica redundante. Você deve considerar que qualquer coisa pode falhar. Caso você tenha uma aplicação que consulte/grave tudo em banco de dados você não terá grandes problemas para manter seu sistema consistente em todas as máquinas, mas caso use alguma aplicação que não está preparada para isso será fundamental ter um sistema de arquivos com replicação.
Imagine um cenário de uma aplicação web comum, ela usa um banco de dados comum para os dados relacionais, mas grava as imagens, arquivos enviados pelos usuários e logs em disco. Caso ocorra uma falha em seu sistema de arquivos, até que você reincie a máquina, faça uma checagem de disco e recupere os dados (se tiver sorte) seu serviço estará offline. Caso tenha um serviço redundante, uma vez que sua máquina falhou a outra máquina ainda estará disponível e seus dados estarão lá, prontos para uso.
Você pode também usar RAID (em software ou hardware) para se proteger de uma falha deste tipo, porém é mais fácil encontrar cenários de várias máquinas de baixo custo do que um hardware de última geração pronto para tudo. Sem contar que a evolução constante faz qualquer hardware por mais caro que seja obsoleto em muito pouco tempo. É muito melhor poder usar um recurso por mais tempo e ter facilidade em descartá-lo do que pagar a manutenção de um serviço especializado.
Para resolver esta replicação de dados existem diversas tecnologias, como Ceph, Lustre e HDFS, porém nunca encontrei uma tão simples e funcional quanto o GlusterFS. O GlusterFS é desde 2011 propriedade da Red Hat e é base para o Red Hat Storage Server. Neste artigo vou apresentar alguns testes que fiz com o GlusterFS e como você pode faze-lo com algumas máquinas usando Debian 8.
Ambiente de teste
Para simular o ambiente usei 4 VMs (criadas no Virtualbox), cada uma delas com 512Mb de RAM + 1 CPU + 8 Gb de disco + Debian 8. Para isolar a rede e separa-la do contexto todas as VMs estavam com uma interface NAT e outra interface de rede interna (na qual o Virtualbox cria uma rede Gigabit entre as VMs) nas quais atribuí IPs fixos:
VM gluster1:
192.168.20.1VM gluster2:
192.168.20.2VM client1:
192.168.20.10VM client2:
192.168.20.11
Para que não ter de usar os IPs diretamente e tampouco ter algum serviço para resolução, ajustamos o arquivo /etc/hosts de todas as máquinas executando em cada uma delas:
echo 192.168.20.1 gluster1 >>/etc/hosts
echo 192.168.20.1 gluster2 >>/etc/hosts
echo 192.168.20.10 client1 >>/etc/hosts
echo 192.168.20.11 client2 >>/etc/hosts
Instalando o GlusterFS no Debian 8
Para instalar o GlusterFS é possível usar o repositório oficial do Debian, porém recomendo instalar a última versão, disponível no site do GlusterFS. Vou considerar que todos os passos daqui em diante você esteja usando o usuário root ou adicionando sudo como prefixo de todos os comandos.
wget -O - http://download.gluster.org/pub/gluster/glusterfs/3.7/3.7.9/pub.key | apt-key add -
echo deb http://download.gluster.org/pub/gluster/glusterfs/3.7/3.7.9/Debian/jessie/apt jessie main > /etc/apt/sources.list.d/gluster.list
apt-get update
# Nas máquinas gluster1 e gluster2
apt-get install glusterfs-server -y
# Nas máquinas client1 e client2
apt-get install glusterfs-client -y
Para outras versões (ou caso os links acima deixem de funcionar) você pode consultar no repositório do glusterfs as URLs adequadas.
Como configurar o GlusterFS
A configuração é muito simples, primeiro criamos uma relação de confiança entre as máquinas gluster1 e gluster2. Na máquina gluster1 executamos
gluster peer probe gluster2
E na máquina gluster2:
gluster peer probe gluster1
Caso ocorra algum erro no processo verifique se seus IPs internos estão funcionando e se o serviço do glusterfs-server está executando (service glusterfs-server status). Se for necessário reinicialize o serviço. Uma vez estabelecida a confiança entre dois servidores você só pode adicionar um novo servidor ao grupo se você realizar o probe a partir de um servidor que já está no grupo.
Agora você pode checar o status de conexão com um gluster peer status.

O GlusterFS se organiza através de volumes, neste caso vamos criar um volume que será armazenado na pasta /glusterfs de cada servidor. Crie a pasta em ambos servidores com um mkdir /glusterfs. Após isso será preciso criar o volume. Este nome de volume é um identificador que você usará quando for montar as unidades nos clientes. Você pode executar este comando em qualquer um dos nós do gluster server que estiverem no cluster:
# sudo gluster volume create <nomedovolume> replica <numerodereplicas> transport tcp maquina:/diretorio maquina2:/diretorio force
# Criando um volume chamado "file", com replica em dois servidores
gluster volume create file replica 2 transport tcp gluster1:/glusterfs gluster2:/glusterfs force
# Inicializando o volume
gluster volume start file
Com isso podemos executar um gluster volume status e checar o volume.

Pronto, hora de montar estes volumes nos nós clientes. Você tem duas opções, pode montar manualmente ou adicionar o mount no fstab. Eu recomendo que você já ajuste no /etc/fstab, para que não perca a configuração ao reiniciar. Então nas máquinas client1 e client2:
# Criamos o diretório onde iremos montar o recurso
# Pode ser qualquer diretório
mkdir /glusterfs
# 1 Alternativa (temporária): Montando manualmente
mount -t glusterfs gluster1:/file /glusterfs
# 2 Alternativa (permanente): Montando pelo fstab
echo gluster1:/file /glusterfs glusterfs defaults,_netdev,backupvolfile-server=gluster2 0 0 >>/etc/fstab
mount -a # Para montar tudo que não foi montado ainda do fstab
Note que na montagem temporária indicamos apenas uma das máquinas, já na montagem permanente podemos atribuir um servidor de backup para a montagem (você pode passar todos os parâmetros pelo mount -o também se desejar). Isso é importante pois imagine que a máquina gluster1 esteja offline e você precise reiniciar a máquina cliente, ela montará a partir do gluster2 o volume sem grandes problemas.
Com isso você está pronto para usar os diretórios.
Testes
Para começar acesse em qualquer um dos clientes o diretório /glusterfs e crie alguns arquivos, note que em todas as máquinas o diretório é modificado quase instantaneamente.
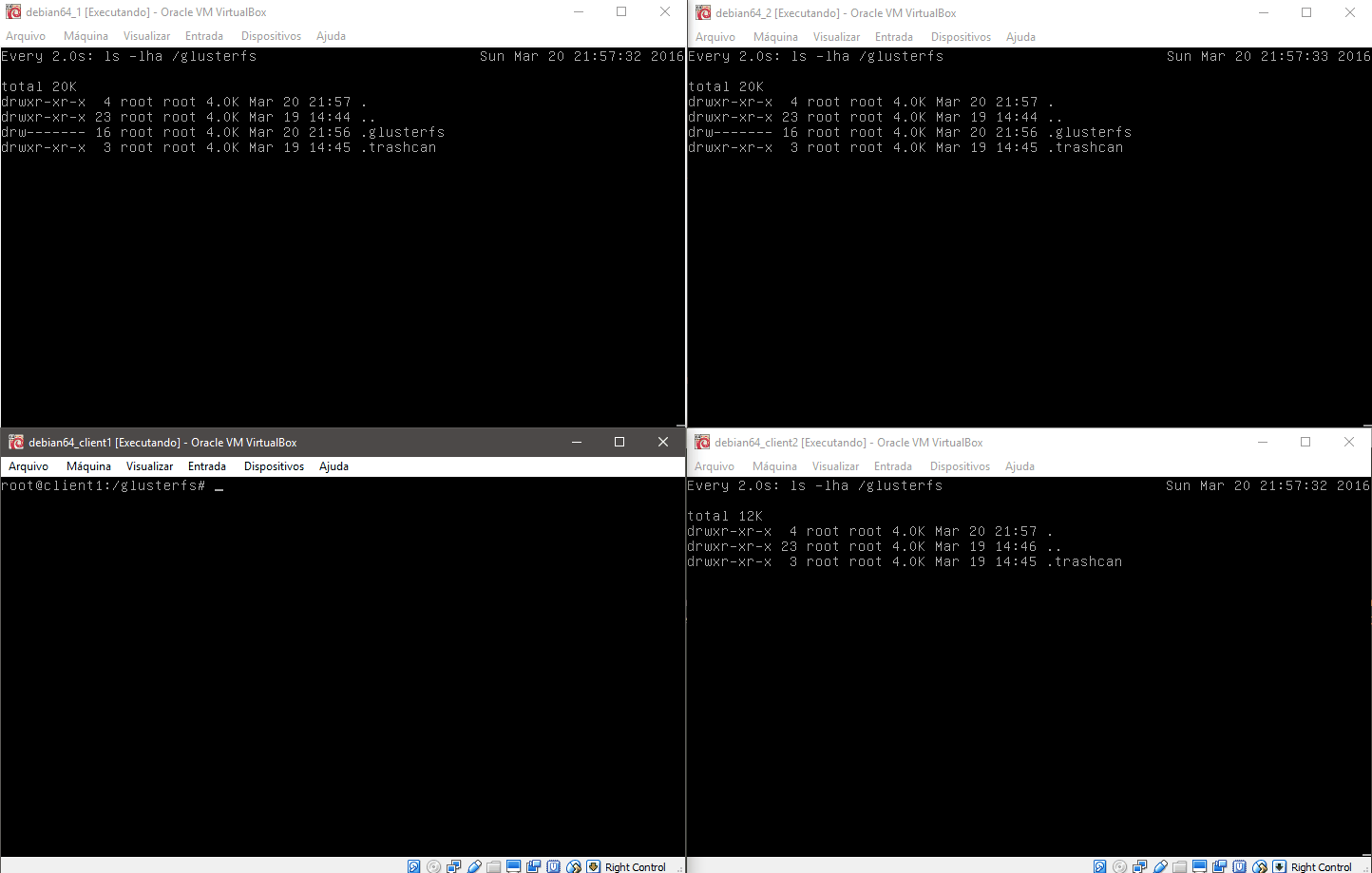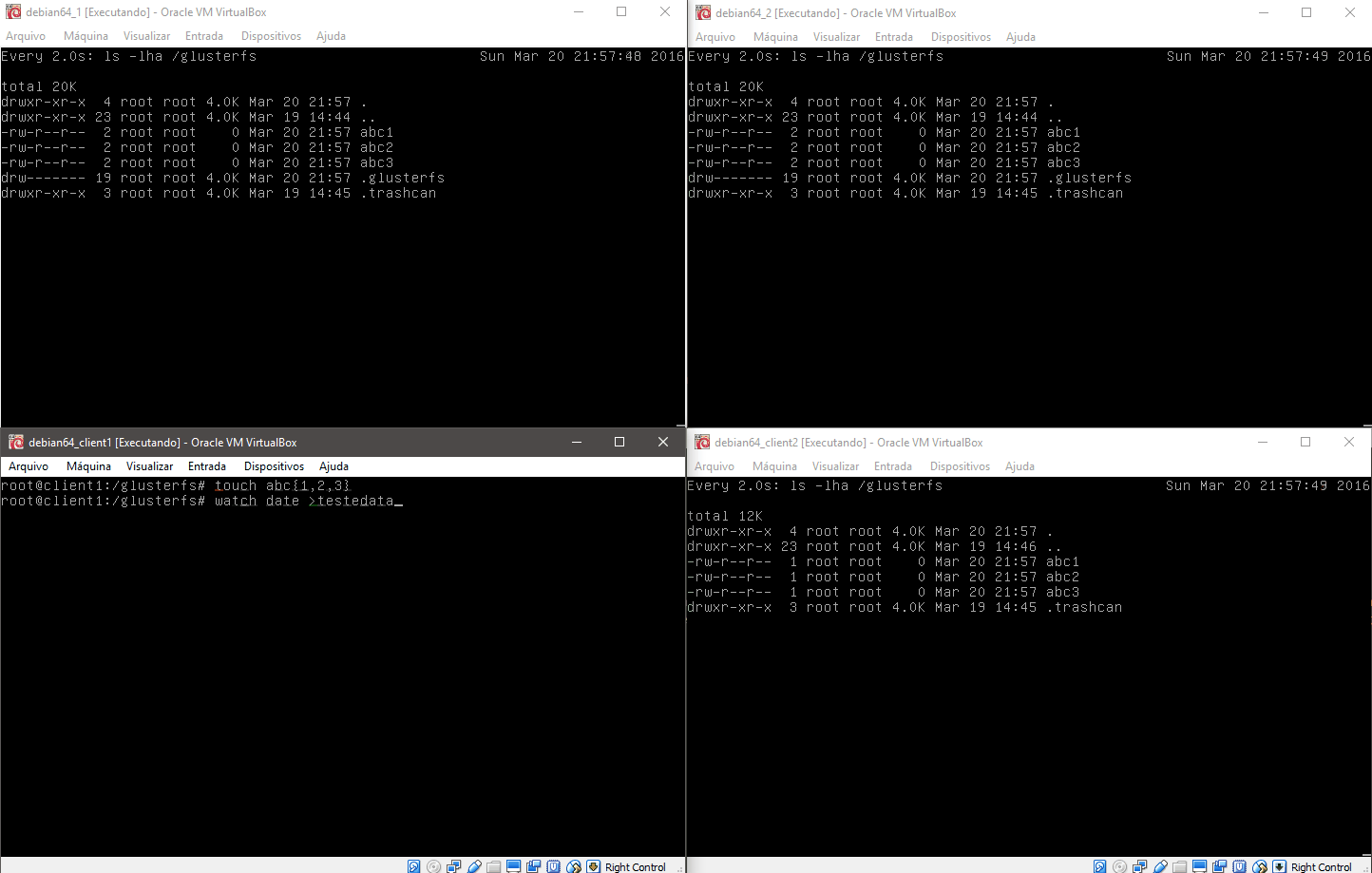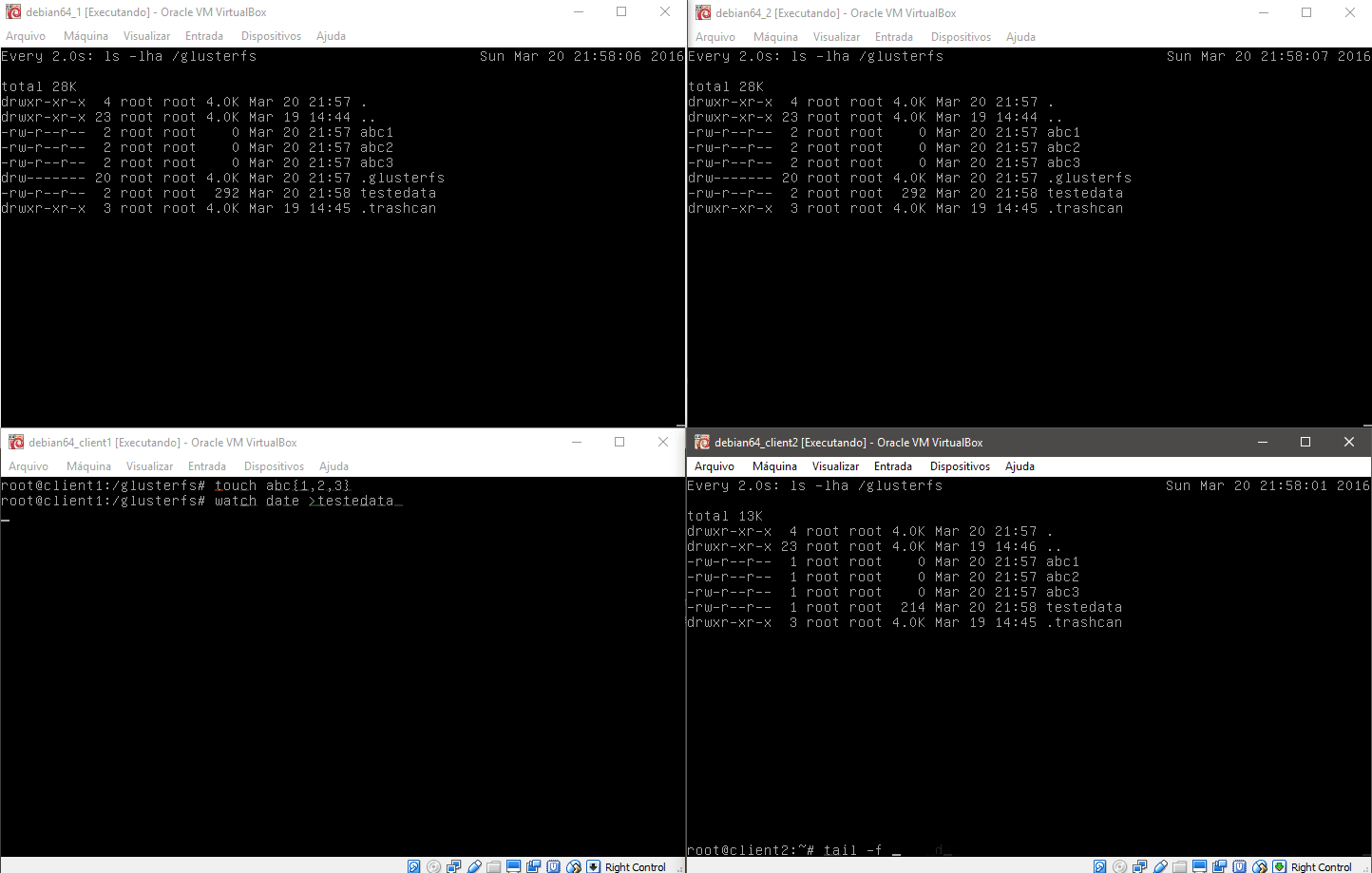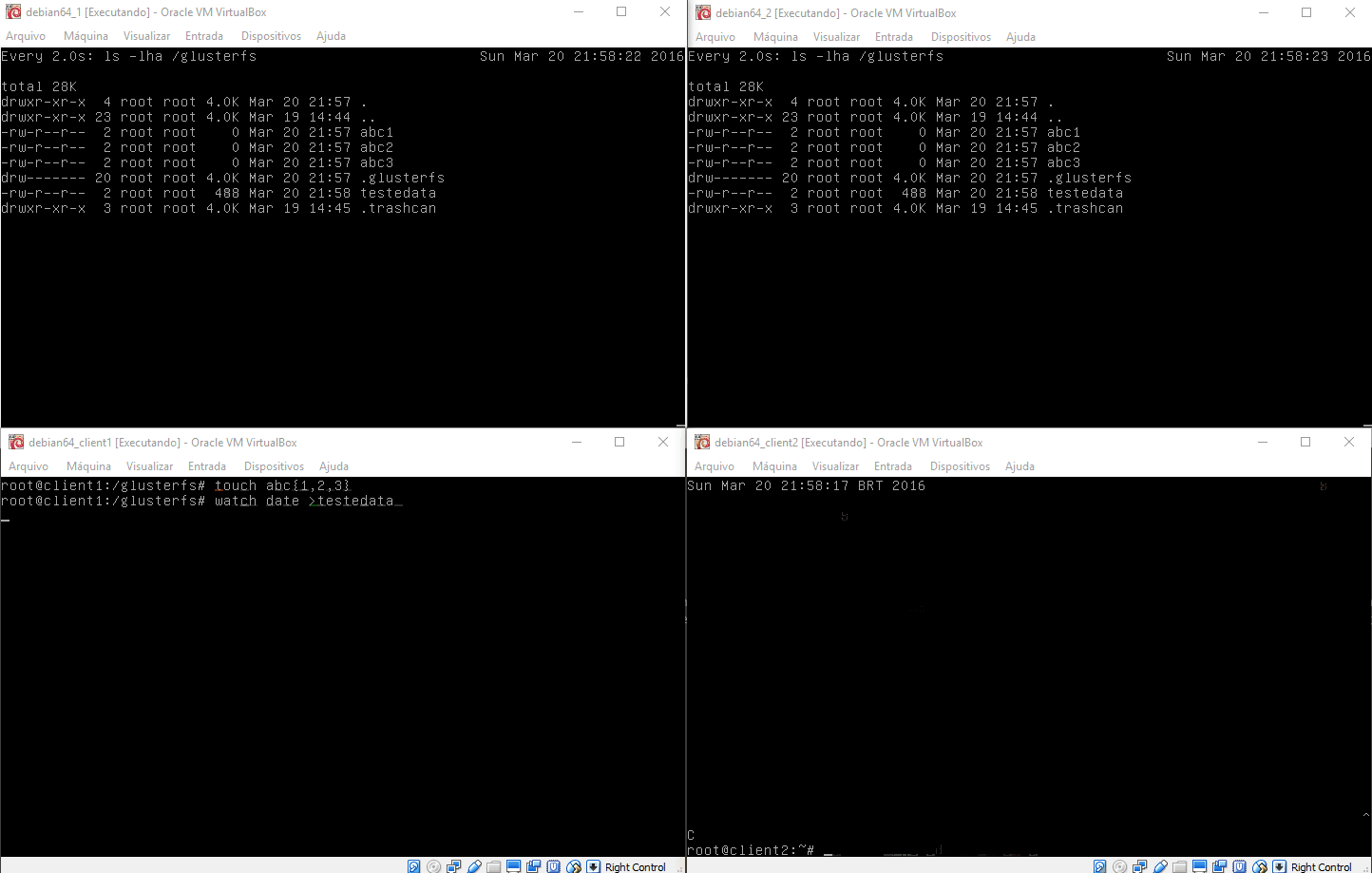
Na imagem acima temos os dois servidores gluster1 e gluster2 na parte superior da imagem e os dois clientes na parte inferior. No teste abaixo realizamos um teste de como o sistema é capaz de regerar-se após uma falha ou travamento.
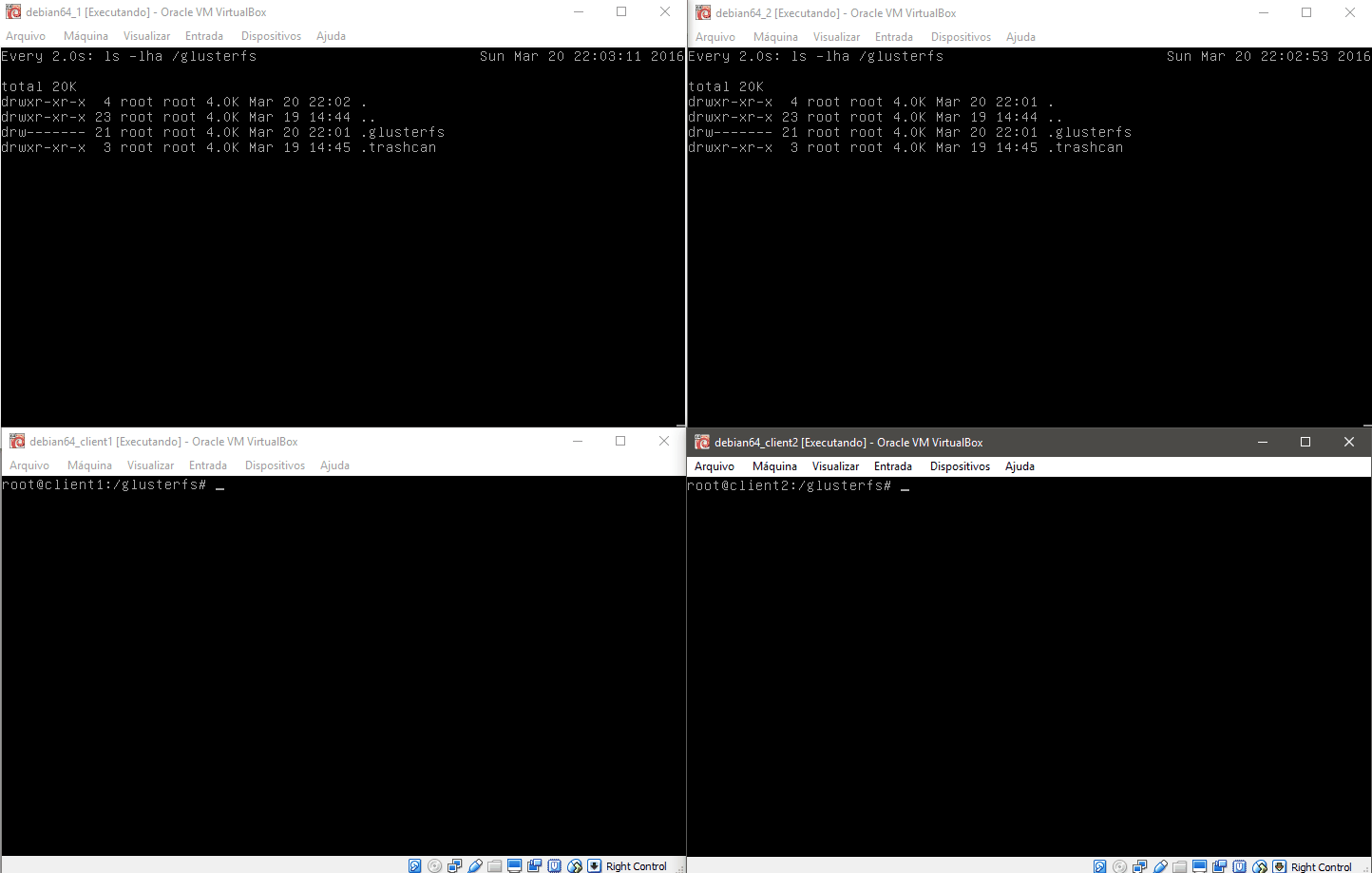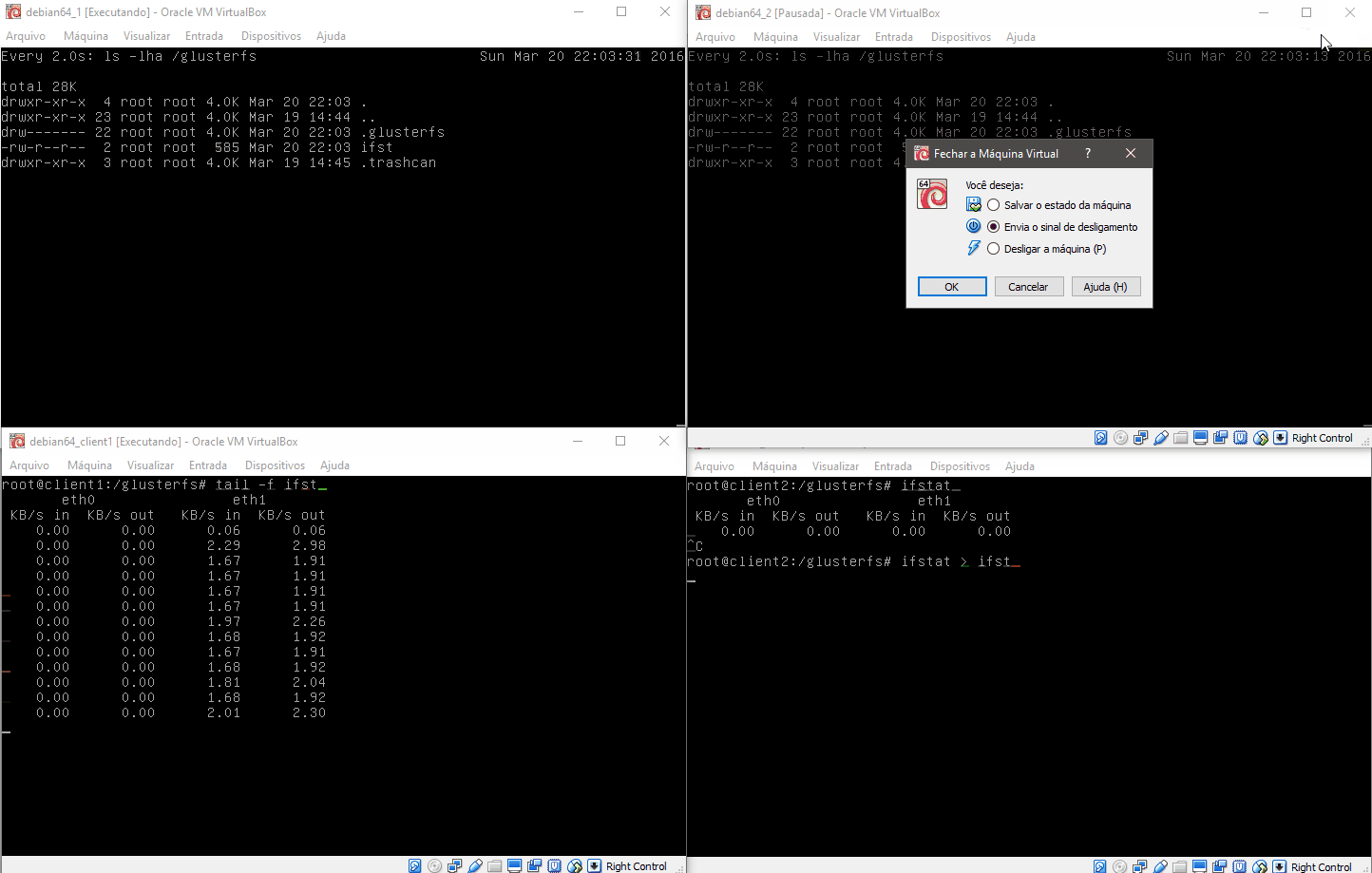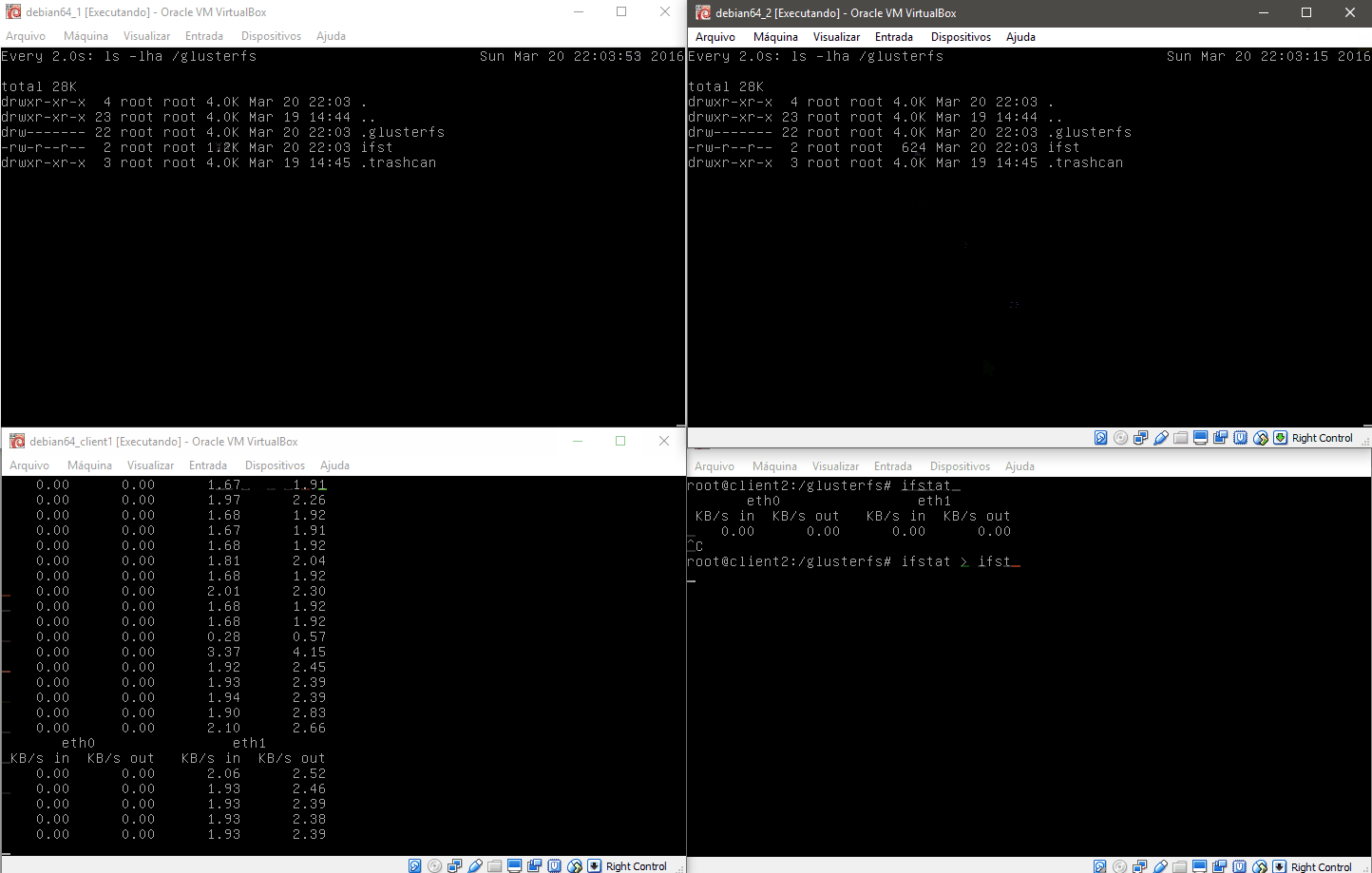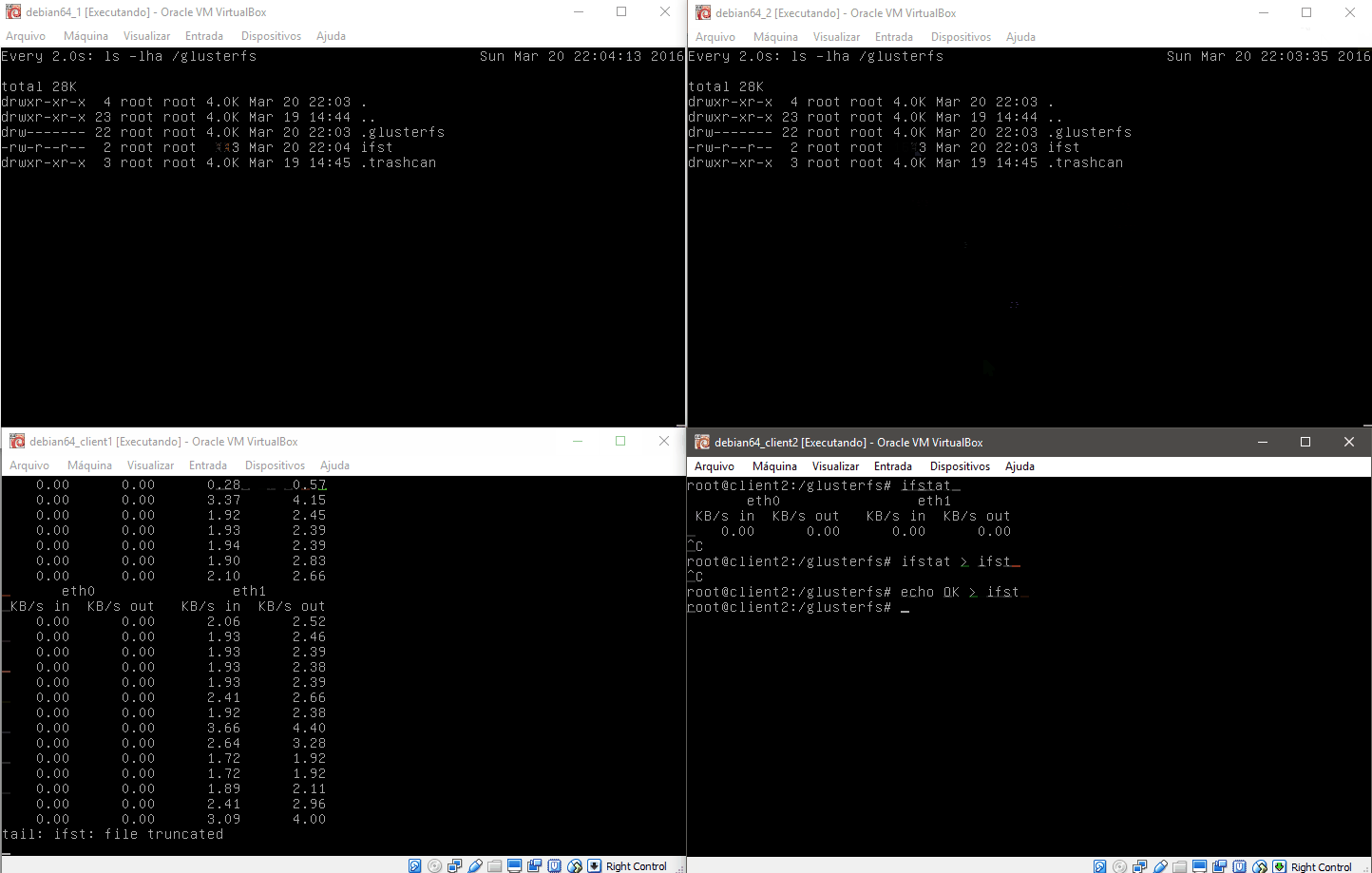
No caso criamos um arquivo que é alimentado continuamente pelo client2, e no client1 lemos este arquivo. Ao pausarmos a máquina gluster2 note que o sistema para de atualizar o client1, e automaticamente volta a alimentar o cluster após o timeout do nó gluster2. Quando voltamos a ativar a máquina gluster2 ela detecta que está com um arquivo desatualizado e o atualiza automaticamente antes de voltar ao cluster.
Conclusões dos testes
O GlusterFS é muito útil para sistemas que persistem dados em disco e é muito fácil de configurar. Nos testes que fiz em uma rede local Gigabit consegui inclusive usar como base para discos de VPS. Há uma grande quantidade de parâmetros de configuração para ajustar pequenos detalhes relacionados a propagação como timeout, buffer, etc.
Não tive a oportunidade de testar em grupos maiores de servidores para avaliar o overhead de controle, porém com duas máquinas facilmente atingia cerca de 80 Mbits de transferência entre as máquinas para sincronização de dados. Um grande número de arquivos pequenos também demoram a propagar entre os nós, criei um script que carregava cerca de 100 mil pequenos arquivos e eles demoraram quase um minuto para propagar entre cada nó.